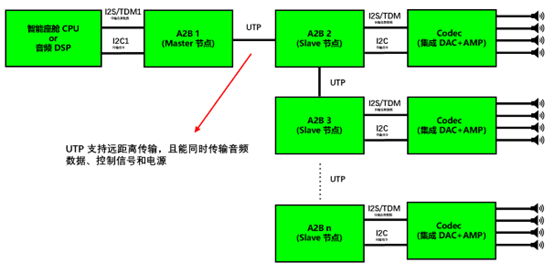
全文目录:
- 前言
- 一、分析函数的高级应用
- 1.1 常见的分析函数
- 1.2 案例演示:使用分析函数排名员工薪资
- 解释:
- 1.3 案例演示:计算累积求和
- 解释:
- 二、模型子句的使用
- 2.1 模型子句的基本结构
- 2.2 案例演示:简单的模型子句应用
- 解释:
- 2.3 模型子句的高级应用
- 三、Oracle中的层次查询与递归查询
- 3.1 使用`CONNECT BY`进行层次查询
- 案例演示:员工层次查询
- 解释:
- 3.2 递归子句的使用
- 案例演示:递归查询计算阶乘
- 解释:
- 四、延伸讨论:模型子句与层次查询的结合
- 案例演示:层次结构中的动态预测
- 结语
前言
在上期内容中,我们详细讨论了**数据定义语言(DDL)**的关键知识点,深入解析了约束的高级使用、视图和同义词的管理以及表分区的设计与实施。这些内容为数据库的结构设计和性能优化打下了坚实的基础。
本期,我们将深入探讨Oracle特有的SQL功能,特别是分析函数的高级应用、模型子句的使用以及层次和递归查询的实现。这些强大的功能为复杂数据分析、动态数据模型的构建以及层次结构处理提供了灵活且高效的解决方案。通过具体的案例演示,大家将更直观地理解如何利用这些Oracle特有的功能,解决日常工作中遇到的复杂查询需求。
一、分析函数的高级应用
分析函数是Oracle SQL中非常强大的功能之一,允许我们在查询中执行复杂的分析操作。与聚合函数不同,分析函数不会对一组结果进行合并,而是在每一行上计算结果,保留行的独立性。它们广泛用于执行窗口操作、排名、累积求和等任务。
1.1 常见的分析函数
Oracle支持多种分析函数,以下是几种常用的函数及其用途:
RANK():用于为结果集中的行生成基于排序的排名,遇到相同的值时跳过排名。DENSE_RANK():与RANK()类似,但不会跳过排名。ROW_NUMBER():为结果集中的每一行生成唯一的行号。LAG()和LEAD():用于在结果集中访问前一行或后一行的值。NTILE():将结果集分成指定数量的桶,并为每一行分配一个桶号。SUM() OVER():用于计算窗口函数中的累积求和。
1.2 案例演示:使用分析函数排名员工薪资
我们假设有一个员工表employees,该表包含员工的ID、姓名、部门和薪资。我们希望按照每个部门对员工进行排名,并保留所有的行。
SELECT
employee_id,
first_name,
last_name,
department_id,
salary,
RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS salary_rank
FROM employees;
解释:
PARTITION BY department_id:根据部门对数据进行分组。ORDER BY salary DESC:根据工资降序排序。RANK():为每个部门中的员工按照工资进行排名。
通过这个查询,我们可以看到每个部门中员工的工资排名,帮助分析不同部门内的薪资分布。
1.3 案例演示:计算累积求和
假设我们有一张销售表sales,希望计算每个月的累积销售额。
SELECT
sale_date,
amount,
SUM(amount) OVER (ORDER BY sale_date) AS cumulative_sales
FROM sales;
解释:
SUM(amount) OVER (ORDER BY sale_date):根据销售日期按时间顺序累计计算销售额。
通过这个查询,我们可以直观地看到随着时间的推移,总销售额的增长情况。
二、模型子句的使用
模型子句是Oracle特有的一个强大功能,允许我们在SQL查询中使用基于多维数组的模型计算。它提供了一种类似电子表格的功能,可以在查询结果上应用复杂的计算规则,并且支持更新、插入和删除等操作。
2.1 模型子句的基本结构
模型子句的基本语法包括三个部分:
- 分区(PARTITION BY):指定如何分割数据集。
- 维度定义(DIMENSION BY):定义模型的维度。
- 规则(MEASURES):指定计算规则和如何更新结果。
2.2 案例演示:简单的模型子句应用
假设我们有一个销售预测表sales_forecast,包含未来几个月的销售预测数据。我们希望使用模型子句来预测未来几个月的销售额变化。
SELECT month, sales, predicted_sales
FROM sales_forecast
MODEL
PARTITION BY ()
DIMENSION BY (month)
MEASURES (sales, 0 AS predicted_sales)
RULES (
predicted_sales[FOR month FROM 2 TO 12] = sales[CV(month) - 1] * 1.1
);
解释:
PARTITION BY ():不进行分区处理。DIMENSION BY (month):定义维度为月份。MEASURES (sales, 0 AS predicted_sales):定义测量值为销售额和预测销售额,初始预测值为0。RULES:定义预测规则,根据前一个月的销售额预测当前月份的销售额。
这个查询基于当前的销售额数据,通过模型子句计算出未来的销售额预测值,假设销售额每月增长10%。
2.3 模型子句的高级应用
模型子句不仅支持简单的线性预测,还可以通过复杂的规则集和条件判断来处理动态的业务需求。例如,可以根据多个维度和条件进行预测分析。
MODEL
PARTITION BY (region)
DIMENSION BY (month)
MEASURES (sales, predicted_sales)
RULES AUTOMATIC ORDER (
predicted_sales[region, month > 1] = sales[region, month - 1] * 1.05
);
在该示例中,模型根据地区分区,并对每个地区的销售数据进行5%的月度增长预测。
三、Oracle中的层次查询与递归查询
层次查询和递归查询是用于处理具有父子关系的数据结构的查询方式。Oracle支持使用CONNECT BY语句来处理层次结构,允许对数据进行递归查询。递归查询通常用于处理组织结构图、目录结构或其他类似的数据。
3.1 使用CONNECT BY进行层次查询
CONNECT BY是Oracle中特有的用于递归查询的子句,结合START WITH可以指定层次结构的起点。该语法特别适合处理有父子关系的表结构。
案例演示:员工层次查询
假设我们有一个员工表employees,其中包含员工ID、姓名以及经理ID(表示该员工的直接上级)。我们可以使用层次查询来查询每个员工的上下级关系。
SELECT employee_id, first_name, last_name, manager_id, LEVEL
FROM employees
START WITH manager_id IS NULL
CONNECT BY PRIOR employee_id = manager_id;
解释:
START WITH manager_id IS NULL:表示查询从顶层(没有上级的员工,即最高领导)开始。CONNECT BY PRIOR employee_id = manager_id:表示递归条件,每个员工的上级对应其经理ID。
通过这个查询,我们可以看到公司员工的层次结构,包括每个员工的层级信息。
3.2 递归子句的使用
Oracle 11g引入了标准SQL递归查询的WITH RECURSIVE语法。递归查询可以实现更灵活的递归数据处理。
案例演示:递归查询计算阶乘
递归查询不仅用于层次结构,还可以用于处理诸如阶乘计算等递归算法。
WITH RECURSIVE factorial(n, fact) AS (
SELECT 1, 1 FROM dual
UNION ALL
SELECT n + 1, fact * (n + 1) FROM factorial WHERE n < 5
)
SELECT * FROM factorial;
解释:
- 该查询通过递归计算1到5的阶乘值。起始值为
n=1和fact=1,每次递归将n增加1,并计算当前的阶乘值。
四、延伸讨论:模型子句与层次查询的结合
在实际应用中,模型子句和层次查询往往可以结合使用,以解决更复杂的数据分析问题。例如,可以使用层次查询构建数据层次结构,再利用模型子句为不同层级的数据执行动态的计算或预测。
案例演示:层次结构中的动态预测
假设我们有一个项目管理表,其中包含项目和子项目的层次结构。我们可以通过层次查询构建结构,并通过模型子句计算各个子项目的预算。
SELECT project_id, parent_project_id, budget, predicted_budget
FROM projects
START WITH parent_project_id IS NULL
CONNECT BY PRIOR project_id = parent_project_id
MODEL
DIMENSION BY (project_id)
MEASURES (budget, 0 AS predicted_budget)
RULES (
predicted_budget[ANY] = budget[CV()] * 1.05
);
该查询首先构建项目的层次结构,然后利用模型子句计算每个项目的预测预算。
结语
本期我们深入探讨了Oracle特有的SQL功能,包括分析函数的高级应用、模型子句的使用和层次与递归查询。通过这些功能,Oracle数据库能够在处理复杂查询和数据分析时提供极大的灵活性与高效性。理解并掌握这些功能,将使您能够更高效地处理大规模数据集,并为业务需求提供精确的分析和预测。
下期内容将重点介绍PL/SQL的简介与环境设置,帮助大家了解Oracle中的过程化编程语言,敬请期待!
参考文献:
- Oracle官方文档
- 数据分析与高级查询技巧


![[Linux] Linux 的进程如何调度——Linux的 O(1)进程调度算法](https://i-blog.csdnimg.cn/direct/2e68aaca6a914648bc6e3b0528c6667f.png)
![LeetCode[中等] 763. 划分字母区间](https://i-blog.csdnimg.cn/direct/de3cea7784674187b67f6ccf68c889fe.png)